When Sprinklers Took Down the Network
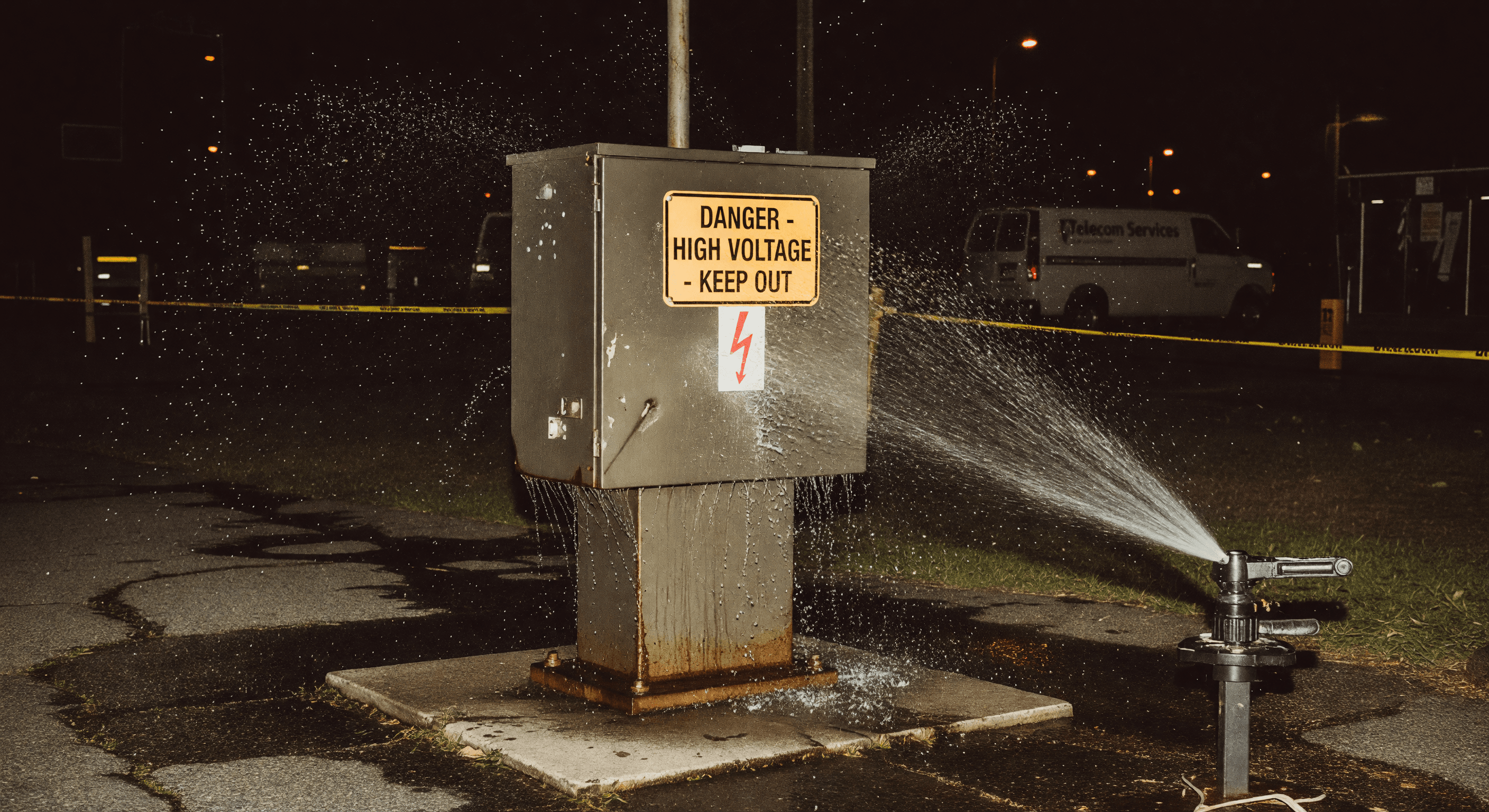
EXHIBIT A: FIELD RECONNAISSANCE // INCIDENT 402
SUBJECT: TELCO DEMARCATION HAZARD
ENVIRONMENTAL THREAT: 3/4" PVC ROTOR SPRINKLER
CLASSIFICATION: MUNDANE / CRITICAL
In March 2026, a drone strike hit an AWS data center in the UAE and the fire department cut all power, generators included. 84 services went down. A few years earlier, I lost a T1 circuit to a landscaping sprinkler. The scale is different. The lesson is the same: infrastructure management doesn't stop at the rack.
I was sitting at Coffee Rush on Dobson when I figured out what had been dropping our T1s for weeks. The landscaping sprinklers kicked on outside. I watched the water arc across the sidewalk and thought: what if that's happening somewhere on our circuit path?
Situation: A growing multi-site healthcare practice connected by point-to-point T1 circuits was experiencing intermittent drops between sites. Short outages, no pattern the ISP could find, no hardware fault on our end.
The Ghost in the Circuit
We were in growth mode. Adding clinics, onboarding providers, running point-to-point T1s between sites. Metro ethernet was on the roadmap but not in the budget yet. The T1s were our lifeline.
Every few days, the circuit between two sites would drop. Five minutes, ten minutes, then back. The ISP ran line tests and found nothing. We replaced the CSU/DSU. We checked the demarc. We watched the monitoring dashboard like it owed us money.
Nothing. Clean tests, dirty results.

The Pattern Nobody Looks For
Then fall overseed hit.
Arizona landscapers water aggressively during overseed. Three times a day: 6 AM, 11 AM, 3 PM. The outages went from weekly to daily. Same times. Every day.
I was at Coffee Rush on Dobson one morning when I watched the sprinklers kick on outside. The water arced across the sidewalk and I thought about the outage pattern. 6 AM, 11 AM, 3 PM. Same times the landscapers water during overseed.
Within hours I was in my car, driving the T1 circuit route between sites, looking for anything exposed. A few blocks from the CO, I found a telco pedestal with a damaged cover. The landscaping sprinklers from the adjacent property were hitting it directly. Water getting into the box, possibly running down the conduit into the terminations.
Wet copper. Intermittent short. Every time the sprinklers ran.
Infrastructure Doesn't Stop at the Rack
The fix was straightforward: get the cover replaced and the wiring protected. The lesson was not.
Nobody puts "landscaping schedule" in a root cause analysis template. But infrastructure runs through places that have nothing to do with IT. Junction boxes on exterior walls. Cable paths that cross irrigation zones. Facilities decisions made by property managers who have never heard of a T1 and have no reason to care.
The same principle applies at every scale. On March 1, 2026, a drone strike hit an AWS data center in the UAE. The local fire department responded by cutting all power to the facility. Primary feeds and backup generators. 84 services went down. Financial institutions lost access. Recovery took over a day.
The fire department didn't care about the SLA.
The DR Question Nobody Asks
Disaster recovery plans typically cover hardware failure, ransomware, and natural disasters. They rarely cover:
- Authority-based shutdowns. Fire marshals, law enforcement, and utility companies can cut power to your facility. They don't need your permission.
- Environmental hazards outside your control. Sprinkler systems, construction crews, landscaping, HVAC water damage. The building is part of your infrastructure whether you manage it or not.
- Shared blast radius. If your production and your DR target share a building, a circuit path, a power feed, or a geopolitical region, a single event can take both offline.
The question isn't whether your backups work. It's whether they work when the building they live in goes dark and stays dark.
What This Looks Like in Practice
If you're responsible for infrastructure that can't go down, audit the physical path. Not just the logical path.
- Where does your circuit enter the building? Is that junction point exposed to weather, construction, or landscaping?
- Does your DR site share a power feed, an ISP, or a geographic risk with production?
- If someone with authority walked into your data center and turned everything off, what happens? How long until you're running somewhere else?
A health check covers exactly this. We audit the VMs, the backups, and the physical dependencies that never show up on a network diagram. The sprinkler timer that nobody thought to check.
Next step
Most engagements start with the Health Check. Fixed fee, clear picture, under two weeks.